Hola, me llamo Mauri y yo también he ignorado las revisiones de código con la excusa de que son «terreno de los desarrolladores».
¡Pero ya no! Desde que trabajo en Atlassian que me he dado cuenta que, para que la calidad escale con el desarrollo, hay que invertir esfuerzos en la prevención por delante del control o la mitigación, y un buen lugar para prevenir son las revisiones de código, que acostumbran a ocurrir antes de cualquier testing hands-on.
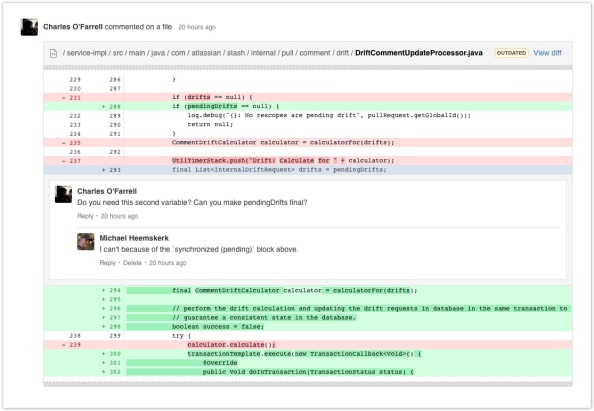
Y no quiero oir a nadie diciendo cosas del estilo «pero yo no soy desarrollador» o «es que no sé leer código», porque no hace falta ser un developercon213añosdeexperiencia para mirarse una revisión de código. Además, leer código es más fácil de lo que aparenta, y las revisiones de código son un buen lugar por donde empezar, ya que los cambios estan asociados a una funcionalidad o bugfix, de tal manera que el código se puede vincular fácilmente a su objetivo.
Listado de 5 cosas al azar que te interesan, como tester, de las revisión de código:
- Mayor conocimiento de los sistemas y aplicaciones: como tester más funcional, seguro que ya te conoces todos los recovecos de la interfaz de usuario, ¿por qué no ampliar ese conocimiento con nociones del funcionamiento de la cara interna de las aplicaciones?
- Inspiración para futuras fases de pruebas: dependencias inesperadas, secciones complejas, condicionales gigantes, dudas sin resolver expresadas en los comentarios… Este tipo de cosas son pistas invaluables para exprimir las aplicaciones durante la fase de pruebas. Este conocimiento, bien usado y con práctica, hace que el testing sea como jugar al Trivial Pursuit consultando la Wikipedia.
- Mejores tests automáticos: el input de un tester en las pruebas automatizadas que vengan con el código (tests unitários, de integración o de lo que sea) puede ser muy útil para que las nuevas funcionalidades nazcan con una cobertura exhaustiva e útil, más allá de los happy paths.
- Se cazan bugs también! Que sí, que sí, que se puede! Y no solo bugs, también comentarios confusos, errores de formato, secciones poco claras, tests unitarios que no testean nada… Las revisiones de código son el momento idóneo para corregir este tipo de problemas.
- Respeto: también puedes ganarte (más) el respeto de los desarrolladores con tu participación e interés en las revisiones de código, gracias a tus consejos y aportaciones en las mismas. Sabrás que estás por el buen camino cuando tu input sea solicitado en ellas o (todavía mejor) cuando algún desarrollador te pida consejo sobre qué casos de prueba automatizar ¡en la fase de codificación!
Estas son las mías, pero hay muchas más razones por las que, como tester, puede ser interesante participar en las revisiones de código. ¿Cuáles son las tuyas? ¡Cuéntamelo en los comentarios!


